

filter mail by html code
I want to filter mail using link locations hidden in the mail's HTML code.
Example: The link visible to the reader might be "Click Here"; but the site it links to might be "UselessScamSite.ru". I want the filter to find and filter according to "UselessScamSite.ru".
Hint: Telling TBird filter to find and delete mail containing "UselessScamSite.ru" in the body (or anywhere else) does NOT work.
How is this done?
Wszystkie odpowiedzi (18)
have you opened the mail using Ctrl+U and checked that the message source actually contains that string?
Yes, I have.
further investigation revealed a bug, and not a new one either.
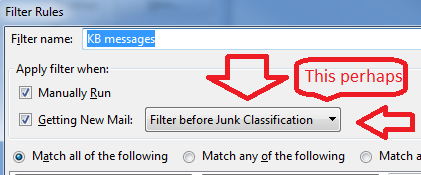
This bug https://bugzilla.mozilla.org/show_bug.cgi?id=750630 Indicates it does not work is the setting is "After Classification" the default.
Change it to before classification and be sure to include setting the message as spam in the filter.
Thanks for the reply; but, I'm not a programmer so I am clueless about what the information at Bugzilla means. Also, I don't see anything in TBird 24.6.0 "Message Filters" about "before classification".
Also, I know how to use spam folders; but, I never have as I have always opted instead for "Delete Message" and "Delete from POP Server".
Thanks for the reply; but, I'm not a programmer so I am clueless about what the information at Bugzilla means. I am not a programmer either, I drive a tractor and work on a farm with my hands.
Also, I don't see anything in TBird 24.6.0 "Message Filters" about "before classification". See the picture
Also, I know how to use spam folders; but, I never have as I have always opted instead for "Delete Message" and "Delete from POP Server".
Your very statement makes it abundantly clear that you do not understand junk mail processing in Thunderbird. Or you would not be calling it a spam folder. Thunderbird documentation talks of junk mail controls and junk mail filtering I suggest you read about the Baysian filter that isbuilt into Thunderbird then you will understand why manually created filters are considered a poor response to junk mail and why training the filter to work for you is a good idea. You will also learn that Thunderbird can detect and delete your junk mail for you.
I'm not an expert concerning filtering mail; but, I do know more than most of my peers and am quite frequently called on to help them solve their computer problems, set up new computers, transfer data from old to new, AND solve e-mail problems. I cannot count the times I have solved a problem of missing mail simply by turning off spam/junk filtering, both on the mail server and in the mail client.
I can appreciate we have a difference of opinion about trusting automated best-guess spam/junk filtering; but, some of the mail I get is just too important to risk to a best-guess, hit and miss. Anyway, the spam/junk folders would have to be inspected before dumping so there would be no net gain.
Thanks for your interest; but, the question remains: How to filter mail by HTML code?
I have answered you twice and have given you a picture of the setting to change. What more can I do?... seriously
I do appreciate your attempts to help.
You have replied with attempts to help me; but, at the risk of sounding (unintendedly) obstinate, I am asking how to have TBird's mail filters detect text hidden in html code and filter according to that finding.
That question is still unanswered.
Eudora would do this as its mail filters were evidently more powerful, more capable than TBirds. I could tell Eudora to find a string of text in the body of a mail and delete that mail. With Eudora, it didn't matter whether that text was hidden in the html code or in the visible text; it got deleted. I would continue with Eudora if it would run full-featured in Windows 7; but, it won't.
I guess TBird just doesn't have that capability.
Again, thanks for trying. I'm sorry I have wasted your time.
Did you even look at this picture? https://support.cdn.mozilla.net/media/uploads/images/2014-07-10-22-30-45-e0c87c.png
{kind=link}
I have never used this forum(?) before I came with this question. It is somewhat confusing. I have checked my settings and they are already the same as you have shown in the picture.
If the picture was referenced before, I didn't know about it, how to access it or see it.
I've just created a test filter and it works perfectly ok.
Tools > Message Filters click on New Give filter a suitable name select 'Manually Run select 'Getting new mail select: Filter before Junk classification
If entering only one condition OR If entering two or more conditions and all conditions must be true select: 'Match all of the following'
If entering two or more conditions and any condition must be true select: 'Match any of the following'
Example using one condition: If you want to search the email content select: BODY and CONTAINS and enter the link eg: www.anje.co.uk
Perform these actions: Choose the action eg: 'Move Message To' and 'Junk on mail account' click on OK
Make sure the filter is enabled.
I then sent an email with words 'My Website' which actually show my website link when you hover over those words.
when email was auto downloaded, the filter detected the email and moved as required. If you already have some emails in Inbox and want to run filter on them: In the Message filters window: disable all other filters - only enable the filter required under 'Run selected filters on: choose Inbox click on 'Run now' button.
please note that filters work in the order listed, so if you have other filters listed above then they may act on the email before this filter could be applied and the email may already have been moved before the second filter runs. so it will not get picked up.
However, if you are trying to set up personalised Junk mail filters on thousands of these types of emails then you should listen to what Matt has suggested. Use and train the Junk Mail Controls. Creating Filters is designed to filter mail as required mainly for organising purposes although you can use it for what you are saying. But training the already in built Junk Mail Controls deals with thousands of similar Junk mail where the parameters/conditions may slightly change enough not to be picked up by a simple self created filter.
Please note that the filter willl only work in the account it is created for. So you would need to manually copy them between mail accounts.
I did as you instructed, step-by-step, rechecked, deleted the filter and did it again. I don't know what is different between here and there; but, it doesn't work here.
One thing you mentioned that is different is that when you "hover", your link appears. That doesn't happen here.
This is the third time I have tackled this problem with help from as many forums and it just looks like Mozilla is just not going to do with filters what Eudora did so well.
I learned the hard way that TB's filters are selectively blind to certain characters. This came to light when someone reported not being able to filter certain addresses and it was found that a + character isn't seen and so can't be used in a filter.
This has taught me to be cautious and to mistrust any non-alphanumeric characters. One way of side-stepping this is to install the FiltaQuilla or the Expression Search/Googlemail GUI add-ons and use regular expression searches where possible.
Do the URLs you are looking for contain any such characters? I'd guess there are a few slashes. I don't know for sure if they are problematic, but let's assume they are…
So far, what I have done is shorten all the very long addresses/links that always contain a plethora of what seems like random characters down to something like "http://www.scammersite.com". TB will not find it if it is in hidden in HTML code. I also tried using only "scammersite.com" and then just "scammersite" as the search criteria, which doesn't even contain any dots or slashes.
Nothing works on anything in HTML code.
All of the addresses I've tried to act on so far contain only standard English letters and not even any numbers.
Also, in all my years of working with computers, the meaning of "regular expression" has eluded me. I guess I just don't have the part of the brain required for that.
It was worth a try.
TB has a quirk in that it searches the html markup, unnecessarily and inappropriately, for spelling errors.
OTOH, I'm seeing reports that there are long-standing bug reports about its inability to filter html markup in message bodies.
If someone could get these two together and iron out their differences, we might get somewhere.
In the meantime…an add-on that provides regular expressions may still help you, since it is using its own custom search engine and applying different rules when parsing text. ISTR that I can, for instance, identify '+' characters in addresses when using regular expressions. (However, '@' remains elusive, but I suspect that it is given very special status in the context of email messages and is blanked out prior to the filter getting to see the message.)
…the meaning of "regular expression" has eluded me…
Does this mean that you know what they are but can't make them work? (a common reaction, they are hard to learn and apply.)
Or that you are still seeking a meaningful description of them?
They are enhanced wildcards. So start by looking at simple wildcards:
dir *.jpg
will, for instance, list only those files whose extension is .jpg
dir a*.jpg
will list only jpegs whose name starts with the letter a.
Now as a contrived example, say we want to find txt files that start with an a, and include some numerals, e.g.
abcd123.txt amno124.txt
I don't know how to use ordinary wildcard searches to make this work. However, a regular expression ("RE") to locate these could be something like this:
/a.*[0-9]+\.txt/
Anatomy:
/: delimiter for the RE pattern a: a literal lower case 'a' .*: any sequence of characters (Formally, any single character, denoted by the period, occurring any number of times, including zero, denoted by the *) [0-9]+: one or more instances of the number characters 0 to 9 (+ is similar to *, but means "at least one") \.: a literal '.' or period. The period is a special character in RE's so we need to escape it with the backslash to disable its special meaning. txt: the literal string "txt" /: closing delimiter
(There are several other ways this could be done.)
The delimiter characters may not be required if you're not using flags. Flags are used to modify the behaviour of the RE, such as setting it to ignore case, or extend over multiple lines.
e.g. if you wanted to accommodate both upper and lowercase letter A, you could use:
[Aa].*[0-9]+\.txt
or:
/a.*[0-9]+\.txt/i
where i is a flag to ignore case.
(To use this RE to list files, we'd need to install and use the grep command line tool or similar, but that's beyond the scope of our current needs.)
The pain with RE's is that there are many flavours of them, FiltaQuilla says it uses a specific Mozilla in-house RE library.
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/RegExp
In broad terms, these are consistent with the POSIX variant of REs.
Zmodyfikowany przez Zenos w dniu
re: One thing you mentioned that is different is that when you "hover", your link appears. That doesn't happen here.
I sent an email with words 'My Website' in the body content, which actually show my website link in the bottom status bar when you hover over those words. In this instance, I'm currently viewing the 'Sent' email copy or the Received email to myself in the 'Inbox', not the new Write message prior to sending.
Are you saying that your received email with eg: The link visible to the reader might be "Click Here"; but when you hover the mouse pointer over 'Click here', there is no actual link eg: http:// www. etc shown in the bottom status bar?
I can confirm that if I 'forward' or 'Reply' to myself using the email I created with the 'My website' link and do not reenter that link in the email content, then the filter will not pick it up as the link is not in the body of the email but in the appended email area. So if you are testing the filter by Replying/forwarding one of those emails to yourself, then it may not get picked up.